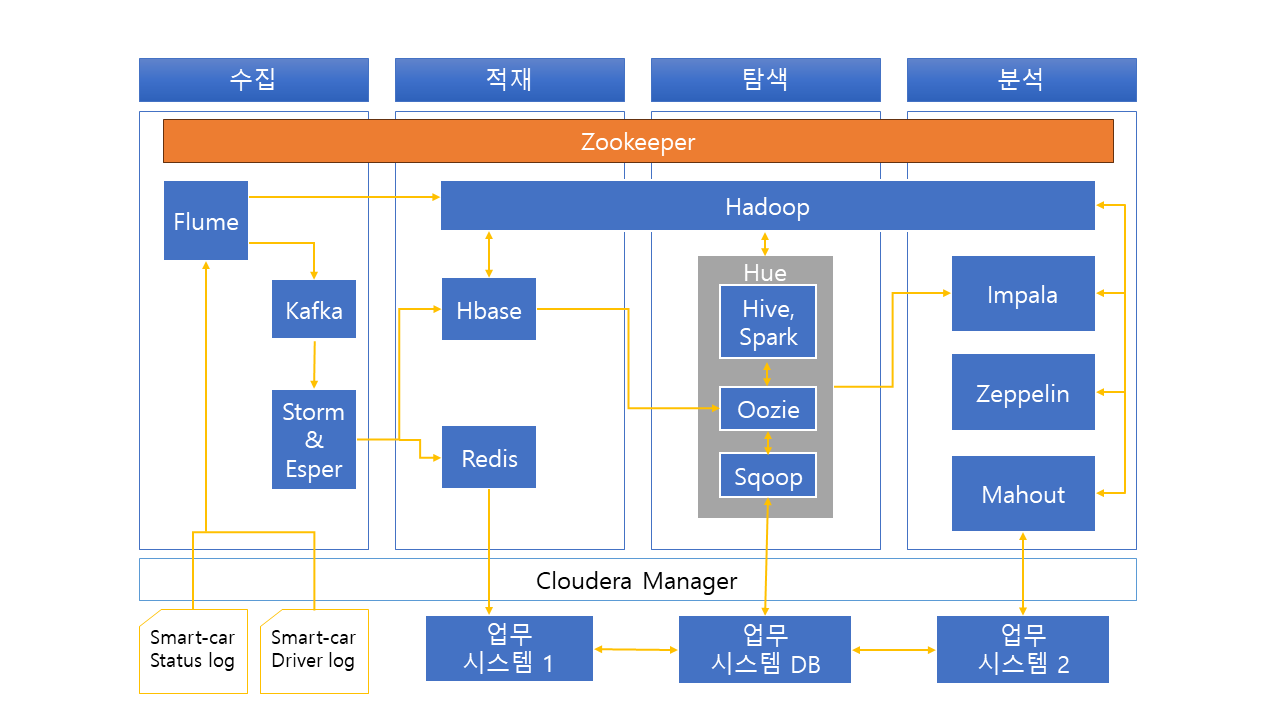
데이터 탐색
탐색 부분은 적재된 데이터를 가공하고 데이터를 이해하는 단계다.
데이터 이해란, 데이터 패턴, 관계등 찾기인데 이를 EDA라 한다.
빅데이터 웨어하우스는 크게 3개로 구성된다.
빅데이터 레이크, 빅데이터 웨어하우스, 빅 데이터 마트이다.
빅데이터 레이크는 수집 부분에서 Flume, Storm등에서 수집한 크고 작은 반정형, 비정형 데이터가 축적되는 곳이다.
빅데이터 레이크에서 데이터가 가공되면, 빅데이터 웨어하우스가 된다.
빅데이터 웨어하우스는 반정규화 Hive 모델이라고 부르기도 하며, EDA가 가능한 부분이며, EDA를 통한 집계, 요약으로 빅데이터 마트를 만든다.
빅데이터 마트는 분석 주제 영역별로 나눌 수 있고, 컬럼지향 Hive 모델이다.
그래서 빅데이터 레이크에서 추출하고, 빅데이터 웨어하우스에서 변환하고, 빅데이터 마트로 만드는 과정을 Hive ETL이라고도 한다.
하이브
- CLI : 사용자가 하이브 쿼리를 입력하고 실행할 수 있는 인터페이스
- JDBC/ODBC Driver : 하이브의 쿼리를 다양한 데이터베이스와 연결하기 위한 드라이버를 제공
- Query Engine : 사용자가 입력한 하이브 쿼리를 분석해 실행 계획을 수립하고 하이브 QL을 맵리듀스 코드로 변환 및 실행, SQL을 입력하면 MapReduce로 변환되고, 이 MapReduce에서 데이터에 대한 결과들을 다시 SQL 쿼리 결과로 보여준다.
- MetaStore : 하이브에서 사용하는 테이블의 스키마 정보를 저장 및 관리하며, 기본적으로 더비 DB(Derby DB)가 사용되나 다른 DBMS(MySQL, PostgreSQL 등)로 변경 가능
이 프로젝트에서는 Flume과 스톰에서 수집한 데이터가 모이는 곳이다.
스파크
맵리듀스는 네트워크 I/O 와 디스크 I/O를 빈번하게 이용되서 하이브 SQL 레이턴시 늦추게 된다.
그래서 스파크는 이 레이턴시를 메모리에 저장하고, 파일을 공유하여 불필요한 네트워크 I/O 와 디스크 I/O를 줄였다.
- Spark RDD : 스파크 프로그래밍의 기초 데이터셋 모델
- Spark Driver / Executors : Driver는 RDD 프로그램을 분산 노드에서 실행하기 위한 Task의 구성, 할당, 계획 등을 수립하고, Executor는 Task를 실행 관리하며, 분산 노드의 스토리지 및 메모리를 참조
- Spark Cluster Manager : Mesos, YARN, Spark Standalone이 있음
- Spark SQL : SQL 방식으로 RDD 프로그래밍 지원
- Spark Streaming : 스트리밍 데이터를 마이크로타임의 배치로 나눠 실시간 처리
- Spark MLib : 스파크에서 머신러닝 프로그래밍(군집, 분류, 추천등) 지원
범용성이 뛰어나며, 데이터에대한 높은 호환성도 있다.
이 프로젝트에서는 '스마트카 마스터' 데이터 정제 처리 후 적재에 사용했다.
우지
Airflow랑 같은 워크플로우 관리 툴이다.
- Oozie Workflow : 주요 액션에 대한 작업 규칙과 플로우를 정의
- Oozie Client : 워크플로우를 Server에 전송하고 관리하기 위한 환경
- Oozie Server : 워크플로우 정보가 잡으로 등록되어 잡의 실행, 중지, 모니터링 등을 관리
- Control 노드 : 워크플로우의 흐름을 제어하기 위한 Start, End, Decision 노드 등의 기능을 제공
- Action 노드 : 잡의 실제 수행 태스크를 정의하는 노드로서 하이브, 피그, 맵리듀스 등의 액션으로 구성
- Coordinator : 워크플로우 잡을 실행하기 위한 스케줄 정책을 관리
이 프로젝트에서는 우지를 하이브QL를 통해 External 영역의 스마트카 상태 데이터와 Hbase의 운전자 운행 데이터를 우지 워크플로우내의 하이브 액션을 통해서 스마트카 상태 데이터, 운전자 운행 데이터, 스마트카 마스터 데이터, 차량용품 구매이력 데이터의 웨어하우스 구축을 위해 사용하였다.
또한,웨어하우스 -> 마트 구축에서도 사용하였다.
휴
- Job Designer : 우지의 워크플로우 및 Coordinator를 웹 UI에서 디자인
- Job Browser : 등록한 잡의 리스트 및 진행 상황과 결과 등을 조회
- Hive Editor : 하이브 QL을 웹 UI에서 작성
- Pig Editor : 피그 스크립트를 웹 UI에서 작성
- HDFS Browser : 하둡의 파일시스템을 웹 UI에서 관리
- HBase Browser : HBase의 HTable을 웹 UI에서 관리
휴의 웹 UI를 이용해 Oozie의 워크플로우 5개를 작성하고 실행

데이터 분석
기술 분석
분석 초기 데이터의 특징을 파악하기 위해 선택, 집계, 요약등의 양적 기술 분석 수행
탐색 분석
업무 도메인 지식을 기반으로 대규모 데이터셋의 상관관계나 연관성을 파악
추론 분석
전통적인 통계분석 기법으로 문제에 대한 가설을 세우고 샘플링을 통해 가설을 검증
인과 분석
문제 해결을 위한 원인과 결과 변수를 도출하고 변수의 영향도 분석
예측 분석
대규모 과거 데이터를 학습해 예측 모형을 만들고, 최근의 데이터로 미래를 예측
임팔라
- Impalad : 하둡의 데이터노드에 설치되어 임팔라의 실행 퀄리에 대한 계획, 스케줄링, 엔진을 관리하는 코어영역
- Query Planner : 임팔라 쿼리에 대한 실행 계획을 수립
- Query Coordinator : 임팔라 잡리스트 및 스케줄링 관리
- Query Exec Engine : 임팔라 쿼리 최적화해 실행, 쿼리 결과 제공
- Statestored : 분산 환걍에 설치돼 있는 Impalad 설정 정보 및 서비스 관리
- Catalogd : 임팔라에서 실행된 작업 이력들을 관리, 작업 이력 제공
임팔라는 실시간 빅데이터 분석 질의가 가능
이 프로젝트에서 임팔라 엔진을 이용해, 대용량 데이터를 실시간으로 Ad-Hoc 분석하였다.
제플린
- NoteBook : 웹 상에서 제플린의 인터프리터 언어를 작성하고 명령을 실행 및 관리할 수 있는 UI
- Visualization : 인터프리터의 실행 결과를 곧바로 웹 상에서 다양한 시각화 도구로 분석해 볼 수 있는 기능
- Zeppelin Server : 웹 제공 웹 애플리케이션 서버
- Zeppelin Interpreter : 데이터 분석을 위한 다양한 인터프리터 제공
이 프로젝트에서 제플린의 Spark SQL로 Ad-Hoc 분석후 결과 시각화하였고, Spark ML로 분류와 군집으로 스마트카 이상징후 예측, 스마트카 고객 성향 분석을 했다.
머하웃
- 추천(Recommendation) : 사용자들이 관심을 가졌던 정보나 구매했던 물건의 정보 분석해서 추천하는 기능이며, 유사 사용자 찾아 추천하는 사용자 기반 추천과 항목 유사성을 계산해 추천하는 아이템 기반 추천등이 존재한다.
- 분류(Classification) : 데이터셋의 다양한 패턴과 특징을 발견해 레이블 지정하고 분류하는 기능으로, 나이브 베이지안, 랜덤 포레스트, 로지스틱 회귀등 지원
- 군집(Clustering) : 대규모 데이터셋에서 새로운 특성으로 데이터의 군집들을 발견하는 기능으로, K-Means, Fuzzy C-Means, Canopy등 지원
- 감독학습(Supervised Learning) : 학습 데이터셋 입력해 분석 모델 학습시키는 머신러닝 기법, 분류와 회귀 분석 기법이 있음
- 비감독학습(Unsupervised Learning) : 학습 데이터셋 없이 데이터의 특징적 패턴을 발견하는 머신러닝 기법, 군집 기법이 있음
이 프로젝트에서는 머하웃을 스마트카 고객 정보의 군집 분석, 차량용품 구매이력 분석으로 스마트카 운전자에게 상품 추천하는 머신러닝 분석으로 사용하였다.
스쿱
- Sqoop Client : 하둡의 분산 환경에서 HDFS와 RDBMS 간의 데이터 Import/Export기능 수행하기 위한 라이브러리로 구성
- Import/Export : RDBMS -> HDFS 경우 Import, HDFS -> RDBMS 경우 Export
- Connectors : Import/Export에서 사용될 다양한 DBMS 접속 어댑터와 라이브러리
- Metadata : 스쿱 서버를 서비스하는데 필요한 각종 메타 정보 저장
이 프로젝트에서 스쿱은 분석한 결과를 외부 RDBMS에 Export하는데 사용하였다.
여기서는 PostgreSQL에 Export..!
이 파일럿 프로젝트를 진행하면서, 데이터를 수집하고, 적재하고, 탐색하며 분석하는 것에 대한 흐름을 볼 수 있는 좋은 기회였다.
다음에 진행할 토이 프로젝트에 이 기술들을 이용할 수 있으면 정말 재밌는 토이 프로젝트가 될 것 같다.
'프로젝트 > 파일럿 프로젝트' 카테고리의 다른 글
| [1] 프로젝트 아키텍처 구성 & 데이터 수집 및 적재 (0) | 2023.12.01 |
|---|

댓글