파일럿 프로젝트의 데이터는 실시간으로 생성되는 로그 데이터인 운전자 운행 정보와 일 단위로 적재되는 대용량 로그 파일인 차량 상태 정보로 구성되어 있다.
따라서, 프로젝트의 전체적인 단계는
- 데이터의 도메인 이해
- 데이터 수집
- 데이터 적재
- 데이터 탐색 및 분석
으로 진행된다.
데이터 정보는 아래와 같다.
데이터 1
- 차량의 다양한 장치로부터 발생하는 로그 파일을 수집해서 기능별 상태 점검
- 데이터 발생 위치 : 100대 시범 운행 차량
- 데이터 종류 : 대용량 로그 파일
- 발생 주기 : 3초
- 수집 주기 : 24시간
- 수집 규모 : 1MB/1대 (총 : 100MB)
- 처리 유형 : 배치
- 데이터유형 : CSV(Text, UTF-8)
데이터 2
- 운전자의 운행 정보가 담긴 로그를 실시간으로 수집해서 주행 패턴 분석
- 데이터 발생 위치 : 100대 시범 운행 차량
- 데이터 종류 : 실시간 로그 파일
- 발생 주기 : 주행관련 이벤트 발생시
- 수집 주기 : 1초
- 수집 규모 : 4KB/1대 (초당 : 약400KB)
- 처리 유형 : 실시간
- 데이터유형 : CSV(Text, UTF-8)
전체적인 프로젝트의 아키텍처는 아래와 같이 구성되어 있다.

데이터 수집
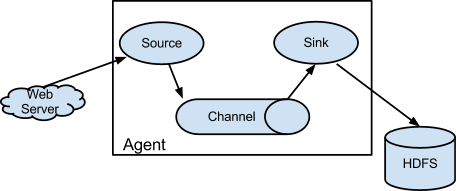
플럼(Flume)
- Source : 다양한 원천 시스템의 데이터 수집하며, Channel에 보내준다.
- Channel : Source 와 Sinck를 연결하며, 데이터를 버퍼링하는 컴포넌트로 메모리, 파일, 데이터베이스를 채널의 저장소로 활용한다.
- Sink : 수집한 데이터를 전달받아 외부로 보내기 위한 기능으로 HDFS, Hive, Logger, Avro, ElasticSearch, Thrift 등 제공한다.
- Interceptor : Source 와 Channel 사이에서 데이터 필터링 및 가공하는 컴포넌트, 필요시 사용자 정의 Interceptor 추가한다.
- Agent : Source > (Interceptor) > Channel > Sink 컴포넌트 순으로 구성된 작업의 단위이며, 독립된 인스턴스로 생성된다.
이 프로젝트에선 스마트카 데이터들을 수집하고, 하둡에 저장하거나 Kafka Topic에 보내주는데 쓰였다.

카프카
- Broker : 카프카의 서비스 인스턴스로서, 다수의 Broker를 클러스터로 구성하고 Topic이 생성되는 물리적 서버
- Topic : Broker에서 데이터의 발행/소비 처리를 위한 저장소, 목적에 맞게 여러개 생성 가능
- Producer : Topic에 데이터를 전송(발행)하는 역할, 메시지 Batch 처리 가능
- Consumer : Topic에서 데이터를 수신(소비)하는 역할, 메시지 Batch 처리 가능
- Partition : 분산 처리를 위해 사용되며, Topic생성시 개수 지정 가능
- Offset : Consumer에서 메세지를 어디까지 읽었는지 저장하는 값, 장애 발생시 마지막으로 읽었던 위치에서 다시 읽어들일 수 있음
이 프로젝트에서 Flume에서 수집한 데이터들을 임시 저장하고, 스톰과 에스퍼를 통해서 데이터를 필터링 후 Hbase, Redis로 보낸다.
스톰&에스퍼
스톰
- Spout : 외부로부터 데이터를 유입받아 가공 처리해서 튜플 생성후 이 튜플을 Bolt에 전송
- Bolt : 튜플을 받아 실제 분산 작업을 수행하며, 필터링, 집계, 조인 등의 연산 병렬 수행
- Topology : Spout/Bolt의 데이터 처리 흐름을 정의하며, 하나의 Spout와 여러개의 Bolt로 구성
- Nimbus : Topology를 Supervisor에 배포하고 작업을 할당, Supervisor를 모니터링하다 필요시 Fail-Over 처리함
- Supervisor : Topology를 실행할 Worker를 구동시키며 Topology를 Worker에 할당 및 관리
- Worker : Supervisor 상에서 실행 중인 자바 프로세스로 Spout/Bolt를 실행
- Executor : Worker 내에서 실행되는 자바 스레드, Executor 개수를 늘리면 분산 처리 가능해짐
- Tasker : Spout/Bolt 객체가 실행되기 위해 Task가 할당
Esper
- Event : 실시간 스트림으로 발생하는 데이터들의 특정 흐름
- EPL : 유사 SQL을 기반으로 하는 이벤트 데이터 처리 스크립트 언어
이 프로젝트에서 Kafka에 임시로 저장된 데이터를 에스퍼 엔진을 통해서 과속시 Redis, 그렇지 않은 데이터들은 Hbase에 보낸다.


데이터 적재


하둡&주키퍼
하둡
- DataNode : 블록(64MB or 128MB 등) 단위로 분할된 대용량 파일들이 DataNode의 디스크에 저장 및 관리
- NameNode : DataNode에 저장된 파일들의 메타 정보를 메모리상에서 로드해 관리
- EditsLog : 파일들의 변경 이력 정보가 저장되는 로그 파일
- FsImage : NameNode의 메모리상에 올라와 있는 메타 정보를 스냅샵 이미지로 만들어 생성한 파일
- Active/Stand-By NameNode: NameNode 이중화, Active NameNode 실패 대비
- MapReduce/YARN : 하둡 클러스터 내의 자원을 중앙 관리하고, 그 위에 다양한 애플리케이션을 실행 및 관리가 가능하도록 확장성과 호환성을 높인 플랫폼
- RosourceManager : 작업 요청시 스케줄링 정책에 따라 자원을 분배해서 실행시키고 모니터링
- NodeManager : DataNode 마다 실행되면서 Container를 실행 시키고 라이프사이클을 관리
- Container : DataNode의 사용 가능한 리소스를 Container 단위로 할당해 관리
- ApplicationMaster : 애플리케이션이 실행되면 생성되며 NodeManager에게 Container를 요청하고 그 위에 애플리케이션을 실행 및 관리
- JournalNode : 3개 이상의 노드로 구성되어 EditsLog를 각 노드에 복제 관리하며 Active NameNode는 EditsLog에 쓰기 수행, Standby NameNode는 읽기 실행
주키퍼
- Client : 주키퍼의 ZNode에 담긴 데이터에 대한 쓰기, 읽기, 삭제 등의 작업을 요청하는 클라이언트
- ZNode : 주키퍼 서버에서 생성되는 파일시스템의 디렉토리 개념으로, 클라이언트의 요청 정보를 계층적으로 관리
- Ensemble : 3대 이상의 주키퍼 서버를 하나의 클러스터로 구성한 HA 아키텍처
- Leader Server : Ensemble 안에 유일한 리더 서버가 선출되어 존재하고, 클라이언트의 요청을 받은 서버는 해당 요청을 리더서버에 전달, 리더 서버는 모든 팔로워 서버에게 클라이언트 요청 전달되도록 보장
- Follower Server : Ensemble 안에서 한 대의 리더 서버를 제외한 나머지 서버로서, 리더 서버와 메시지를 주고받으면서 ZNode의 데이터를 동기화하고 리더 서버에 문제가 발생할 경우 내부적으로 새로운 리더를 선출하는 역할 수행
이 프로젝트에서 HDFS에는 날짜 별로 디렉토리가 만들어지고, 데이터가 블럭 사이즈로 나뉘어 저장되는 걸 볼 수 있다.


Hbase&Redis
Hbase
- HTable : 칼럼 기반 데이터 구조를 정의한 테이블로, 공통점이 있는 칼럼들의 그룹을 묶은 칼럼 패밀리와 테이블의 로우를 식별해 접근하기 위한 로우키로 구성
- HMaster : HRegion 서버를 관리하며, HRegion들이 속한 서버의 메타 정보를 관리
- HRegion : HTable의 크기에 따라 자동으로 수평 분할이 발생하고, 이때 분할된 블록을 HRegion 단위로 지정
- HRegionServer : 분산 노드별로 구성되며, 하나의 서버에는 다수의 HRegion이 생성되어 HRegion을 관리
- Store : 하나의 Store에는 칼럼 패밀리가 저장 및 관리되며, MemStore와 HFile로 구성됨
- MemStore : Store 내의 데이터를 인메모리에 저장 및 관리하는 데이터 캐시 영역
- HFile : Store 내의 데이터를 스토리지에 저장 및 관리하는 영구 저장 영
Redis
- Master : 분산 노드 간의 데이터 복제와 Slave 서버의 관리를 위한 마스터 서버
- Slave : 다수의 Slave 서버는 주로 읽기 요청을 처리하고, Master 서버는 쓰기 요청을 처리
- Sentinel : 레디스 3.x 부터 지원하는 기능으로, Master 서버에 문제가 발생할 경우 새로운 Master를 선출하는 기능
- Replication : Master 서버에 쓰인 내용을 Slave 서버로 복제해서 동기화 처리
- AOF/Snapshot : 데이터를 영구적으로 저장하는 기능으로, 명령어를 기록하는 AOF와 스냅샷 이미지 파일 방식을 지
이 프로젝트에서 Hbase에는 날짜가 거꾸로 입력되며, Hbase에는 모든 운행자 정보가 적재 되고, Redis에는 과속한 운전자 정보만 적재된다.

'프로젝트 > 파일럿 프로젝트' 카테고리의 다른 글
| [2] 데이터 탐색 & 분석 (1) | 2023.12.04 |
|---|

댓글