GCP VM으로 Airflow 구축하기
이전에는 로컬에서의 Airflow를 구축했으니, 이번에는 구글 클라우드 플랫폼의 VM(가상머신)을 이용한 Airflow를 구축(?)하는 시간이다.
구글 클라욷 플랫폼에서 새로운 프로젝트를 만들어준다.

Airflow를 작동시킬 메인 VM을 만들어준다.(vCPU : 2개, RAM : 8GB를 main node로)
Compute engine의 VM 인스턴스에서 인스턴스 만들기를 눌러 만들어준다.
(worker node는 vCPU : 2개, RAM : 4GB로 만들어준다)
(리전과 영역은 만약 기존에 쓰는 다른 서비스가 있다면, 맞춰주는게 좋은것 같다)


우분투가 편해서 우분투로 설정하고, 방화벽에서 HTTP/HTTPS의 트래픽 허용을 체크한다.
이렇게 만들어주면 main-node VM 생성..
인스턴스 생성이 완료가 되었다면 SSH를 통하여 연결하고, 필수적인 기본 환경을 설치해준다.
(Airflow, Postgresql, Rabbitmq)


sudo apt-get update
sudo apt-get install postgresql
# postgresql 설치해주기
sudo apt-get install rabbitmq-server
# rabbitmq 설치해주기

# 대쉬보드 활성화
sudo rabbitmq-plugins enable rabbitmq_management
# 시작시 서버 자동 활성화
sudo systemctl enable rabbitmq-server
# 유저 생성, 관리자 부여, 권한 부여
# 유저 생성
sudo rabbitmqctl add_user admin admin
# 관리자 부여
sudo rabbitmqctl set_user_tags admin administrator
# 권한부여
sudo rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"
rabbitmq가 잘 구동되는지 확인
(모든 인스턴스의 경우)
GCP의 VCP 네트워크 -> 방화벽 -> 방화벽 규칙 만들기 -> 이름부여, 모든 인스턴스 선택
-> IPv범위 설정(테스트라서 0.0.0.0/0 으로 설정함) -> 포트는 TCP선택후 15672 입력 후 만들기
(메인노드의 외부IP:15672치면 잘 들어가는걸 볼 수 있다.)
(태그시 태그 이름 설정의 경우)
GCP의 VCP 네트워크 -> 방화벽 -> 방화벽 규칙 만들기 -> 이름부여, 태그(태그시 태그 이름 설정)
-> IPv범위 설정(테스트라서 0.0.0.0/0 으로 설정함)
-> (태그 설정시) 인스턴스로 돌아가서 main-node 선택 -> 수정 클릭 -> 네트워크 태그에 설정한 태그이름 입력후 저장 -> 끝!(메인노드의 외부IP:15672치면 잘 들어가는걸 볼 수 있다.)



이제 airflow.cfg파일을 수정하기
executor = CeleryExecutor
load_examples = False
sql_alchemy_conn = postgresql+psycopg2://postgres_id:postgres_pass@localhost/airflow_db
broker_url = amqp://rabbitmq_id:rabbitmq_password@localhost:5672/
result_backend = db+postgresql://postgres_id:postgres_pass@localhost/airflow_db
# 위처럼 airflow.cfg 파일 변경해줃기airflow user까지 만들기!!(전에 포스팅한것 참조)
rabbitmq와 똑같이 포트별로 방화벽 규칙 만들어주기!
airflow webserver : 8080
postgresql : 5432
flower : 5555
위와 같이 했다면, 이제 worker node의 설정을 진행하면 된다.
main node에서의 설정중 airflow, postgresql, celery를 설치한다.
그리고 두 VM의 NTP 설정을 통하여 시간대를 맞춰준다.
아래는 main node에서 다음과 같이 설정을 변경해준다.
# 방화벽 설정을 바꿔준다
sudo ufw allow from 'public_ip' to any port 8080
sudo ufw allow from 'public_ip' to any port 5672
sudo ufw allow from 'public_ip' to any port 15672
sudo ufw allow from 'public_ip' to any port 5555
sudo ufw allow from 'public_ip' to any port 5432/etc/postgresql/12/main에서 postgresql.conf에서
listen_addresses = 'localhost'
#위에서 아래와 같이 바꿔준다
listen_addresses = '*'pg_hba.conf에서
# IPv4 local connections:
host all all 127.0.0.1/32 md5
# 에서 아래와 같이 바꿔준다!
# IPv4 local connections:
host all all 0.0.0.0/0 md5
# main node에서
airflow celery worker -D -q queue1
# worker node에서
airflow celery worker -D -q queue2
# 를 쳐서 워커를 활성화 시킨다!만약에 위 방식으로 성공을 했다면!?!?!

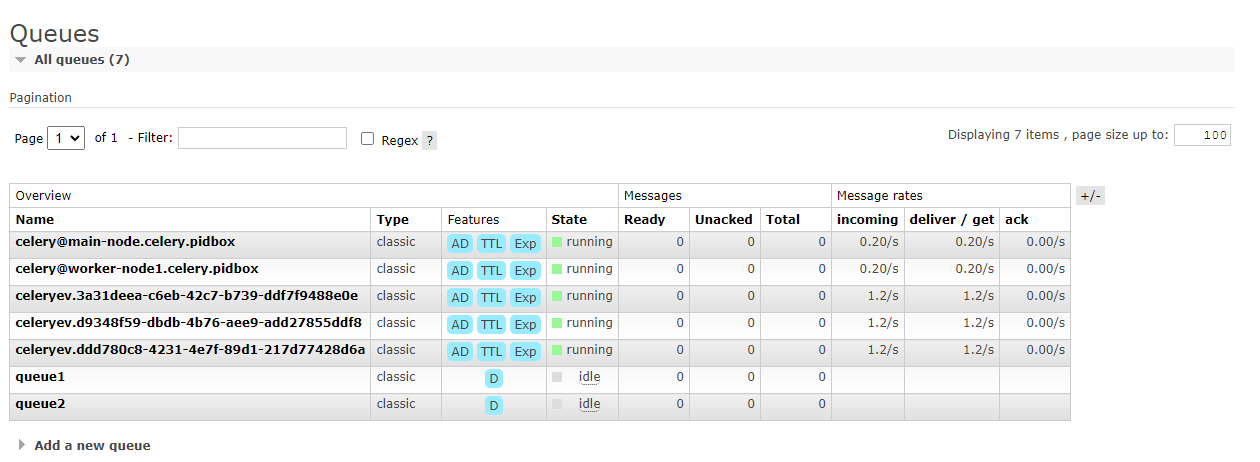

다음과 같이 main node와 worker node가 온라인인 것을 볼 수 있다!!!!
출처
Tianlong's Blog - A Guide On How To Build An Airflow Server/Cluster (stlong0521.github.io)
Tianlong's Blog - A Guide On How To Build An Airflow Server/Cluster
A Guide On How To Build An Airflow Server/Cluster Sun 23 Oct 2016 by Tianlong Song Tags Big Data Airflow is an open-source platform to author, schedule and monitor workflows and data pipelines. When you have periodical jobs, which most likely involve vario
stlong0521.github.io
[airflow] 4. CeleryExecutor 사용하기 (sanghun.xyz)
[airflow] 4. CeleryExecutor 사용하기
Airflow CeleryExecutor 사용하기
sanghun.xyz
[Airflow] Airflow cluster, celery executor + flower + RabbitMQ 환경 구성하기 (tistory.com)
[Airflow] Airflow cluster, celery executor + flower + RabbitMQ 환경 구성하기
이번 포스트에는 AWS EC2 3대로 구성된 airflow cluster를 CeleryExecutor로 설치해보겠습니다. 서버 구성 스펙 OS - Amazon linux2 AMI (HVM) - Kernel 5.10, SSD Volume type instance type - t2.Large 2vCPUs, 8GiB Memory storage - 30GB gp2
spidyweb.tistory.com