-
Hive, Presto, Impala데이터엔지니어링/빅데이터 2023. 2. 24. 00:26
Hive
Hive는 Hadoop ecosystem에서 데이터 웨어하우스 시스템을 담당하고 있으며, 대규모 배치 처리를 하는 쿼리 엔진이며, 데이터양에 좌우되지 않는 쿼리 엔진이다.
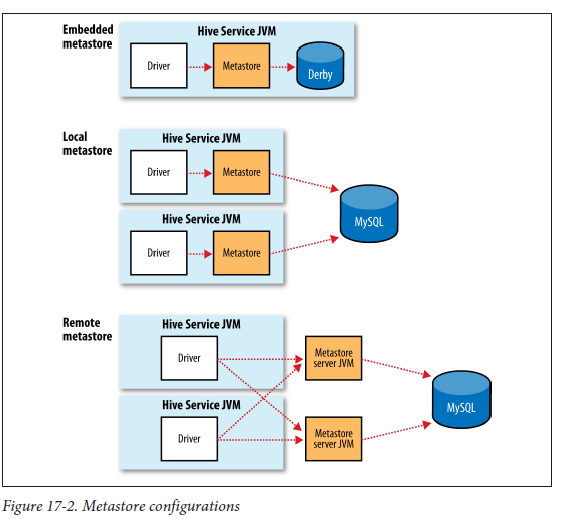
Hive는 Hive Metastore가 있는데, 여기는 데이터들을 저장하고 스키마를 이용해 구조화하여 저장하는 곳이다.
특히, 텍스트 데이터를 가공하거나 열 지향 스토리지를 만드는것 같은 무거운 처리의 경우 Hive를 사용하는게 적합하다.
Hive의 특징 및 한계
특징
Hive는 빠르고 확장성이 있다.
MapReduce 나 Spark 작업으로 변환되는 SQL 같은 쿼리를 제공한다.HDFS에 저장된 대용량 데이터 세트를 분석 가능하다.
인덱싱을 사용해 쿼리를 가속화한다.
Hadoop 에코시스템에 저장된 압축 된 데이터에서 작동할 수 있다.
한계점
Hive는 실시간 데이터 처리가 불가능하다.
온라인 트랜잭션 처리를 위해 설계하지 않는다.
Hive 쿼리는 latencty가 길다.
Impala
Impala는 Hive와 동일한 메타데이터, SQL 구문, ODBC 드라이버를 사용해 일괄 처리 지향 이나 실시간 쿼리를 위해 통합된 플랫폼을 제공한다.
Impala의 장점
데이터 노드의 에서 로컬 프로세싱으로 네트워크 병목 현상을 방지된다.
통합된 단일 개방형 메타데이터 저장소를 활용할 수 있다.
데이터 형식 변환이 필요치 않아 오버헤드가 발생하지 않는다.
모든 데이터는 ETL에 대해 지연 없이 즉각 쿼리가 가능하다.
모든 하드웨어는 MapReduce뿐만 아니라 Impala 쿼리에도 사용된다.
스케일을 조정하는데 single machine pool만 필요하다.

Impala (apache.org) Presto
윈도우 함수를 비롯한 표준 SQL을 준수하고 있고, 일상적인 데이터 분석을 위해 자주 사용되는 쿼리 엔진으로 Hadoop, MySQL, Cassandra, Mongo DB 등 많은 데이터 스토어에 대응이 되어 모든 데이터를 SQL로 집계할 수 있다.
Presto는 대화식 쿼리의 실행에 특화되어 텍스트 처리가 중심이 되는 ETL 프로세스 및 데이터 구조화에는 적합하지 않다. 다만, 열 지향 스토리지를 만드는 데 사용할 수 없다는 건 아니지만, 적합하지는 않다. 데이터 구조화시 Spark나 Hive를 사용하는게 좋다.
Presto 쿼리는 단 시간에 대량의 리소스를 사용하기 때문에, 배치 처리는 Hive에 주거나 클러스터를 나누는등으로 Presto가 대화식 쿼리를 위해 리소스를 아끼게 해야한다.

presto 쿼리 실행 과정 '데이터엔지니어링 > 빅데이터' 카테고리의 다른 글
Hadoop 도입 (1) 2023.02.17 데이터 웨어하우스, 레이크, 마트, ETL (0) 2023.02.06