-
[5장] 스파크 SQL과 데이터 프레임: 외부 데이터 소스와 소통하기데이터엔지니어링/Spark 2023. 9. 5. 02:32
이번 장은 스파크 SQL을 사용해 다음을 수행하는 방법에 대해서 알아보자.
- 아파치 하이브 및 아파치 스파크 모두에 대해 사용자 정의 함수를 사용하기
- JDBC 및 SQL 데이터 베이스, PostgreSQL, MySQL, 태블로, 애저 코스모스 DB 및 MS SQL 서버와 같은 외부 데이터 원본과 연결하기
- 단순하거나 복잡한 유형, 고차 함수 그리고 일반적인 관계 연산자 사용하기
스파크 SQL과 아파치 하이브
스파크 SQL은 관계형 처리와 스파크의 함수형 프로그래밍 API를 통합하는 아파치 스파크의 기본 구성 요소다.
사용자 정의 함수(UDF)
스파크는 내장 함수도 제공하지만, 자신의 기능을 정의할 수 있는 유연성 또한 제공이 되며, 이를 사용자 정의 함수라 한다.
스파크 SQL UDF
사용자가 UDF를 생성하는 이점은 사용자(다른 사용자)도 스파크 SQL에서 이 함수를 사용할 수 있다는 점이다.
여기서 UDF는 세션별로 작동하고, 기본 메타 스토어에서는 유지되지 않는다.
from pyspark.sql.types import LongType # 큐브 함수 생성 def cubed(s): return s * s * s # UDF 등록 spark.udf.register("cubed", cubed, LongType()) # 임시 뷰 생성 spark.range(1, 9).createOrReplaceTempView("udf_test") spark.sql("SELECT id, cubed(id) AS id_cubed FROM udf_test").show()
show()를 사용했을때 결과값
스파크 SQL에서 평가 순서 및 null 검사
스파크 SQL은 평가 순서를 보장하지 않으므로, 적절한 null 검사를 위해서 다음을 수행해야 한다.
- UDF 자체가 null을 인식하도록 만들고 UDF 내부에서 null 검사를 수행한다.
- IF 또는 CASE WHEN을 사용해 null 검사를 수행하고 조건 분기에서 UDF를 호출한다.
판다스 UDF로 파이스파크 UDF 속도 향상 및 배포
파이스파크 UDF는 JVM과 파이썬 간의 데이터 이동이 필요해서 성능이 느린데, 이를 해결하기 위해 판다스 UDF(벡터화된 UDF라고도 함)가 도입이 되었다.
판다스 UDF를 통해서 데이터의 직렬화나 피클링 할 필요가 없어졌고, 판다스 시리즈 혹은 데이터 프레임에서 작업을 할 수 있게 되었는데, 이는 아파치 애로우를 사용해 데이터를 전송하기 때문이다.
판다스 UDF는 판다스 UDF 와 판다스 함수 API로 분할되어 있다.
판다스 UDF
시리즈나, 시리즈 반복자, 다중 시리즈 반복자, 스칼라를 파이썬 유형 힌트로 지원 한다.
판다스 함수 API
입력과 출력이 모두 판다스 인스턴스인 파이스파크 데이터 프레임에 로컬 파이썬 함수를 직접 적용할 수 있으며, 그룹화된 맵, 맵, 공동 그룹화된 맵을 지원한다.
import pandas as pd from pyspark.sql.functions import col, pandas_udf from pyspark.sql.types import LongType # 큐브 함수 선언 def cubed(a: pd.Series) -> pd.Series: return a * a * a # 큐브 함수에 대한 판다스 UDF 생성 cubed_udf = pandas_udf(cubed, returnType=LongType())# 판다스 시리즈 생성 x = pd.Series([1, 2, 3]) # 로컬 판다스 데이터를 실행하는 pandas_udf에 대한 함수 print(cubed(x))
print()의 결과 # 스파크 데이터 프레임 생성 df = spark.range(1, 4) # 벡터화된 스파크 UDF를 함수로 실행 df.select("id", cubed_udf(col("id"))).show()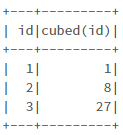
show()의 결과
스파크 SQL 셸
스파크 SQL 쿼리를 실행하는 방법 중 하나는 spark-sql CLI다. 이 유틸리티는 로컬 모드에서 하이브 메타스토어 서비스와 통신하는 대신 JDBC/ODBC 서버 (스파크 쓰리프트 서버(STS))와 통신하지 않고, STS를 사용 시 JDBC/ODBC 클라이언트가 아파치 스파크에서 JDBC 혹은 ODBC 프로토콜을 통해 SQL 쿼리를 실행할 수 있다.
비라인 작업
하이브QL 쿼리를 실행하기 위한 유틸리티인 비라인 커맨드라인 툴을 이용하며, 비라인은 SQLLine CLI를 기반으로 하는 JDBC 클라이언트다. 비라인을 이용해 스파크 스리프트 서버에 대해 스파크 SQL 쿼리를 실행할 수 있다.
태블로로 작업
쓰리프트 JDBC/ODBC 서버를 통해 선호하는 BI 도구를 스파크 SQL에 연결할 수 있다.
JDBC 및 SQL 데이터베이스
스파크 SQL에는 JDBC로 다른 데이터베이스에서 데이터를 읽을 수 있는 데이터 소스 API가 포함되어 있다.
결과를 데이터 프레임으로 반환 시 이러한 데이터 소스 쿼리를 단순화해 스파크 SQL의 이점을 준다.
파티셔닝
스파크 SQL과 JDBC 외부 소스 간 많은 양의 데이터를 전송할 때 데이터 소스를 분할하는 게 중요하다.
하나의 드라이버 연결을 통해 모든 데이터가 처리되기 때문이다.
파티셔닝 연결 속성은 다음과 같다.
- numPartitions : 테이블 읽기 및 쓰기에서 병렬 처리를 위해 사용할 수 있는 최대 파티션 수이며, 최대 동시 JDBC 연결 수를 결정한다. [스파크 워커 수의 배수를 사용하는 게 좋다.]
- partitionColumn : 외부 소스 읽을 때 파티션을 결정하는 데 사용되는 컬럼으로, 숫자, 날짜 또는 타임스탬프 컬럼이어야 한다. [실제 값을 기준으로 적절하게 분배하는 게 좋으며, 데이터 스큐를 방지하도록 균일 분산될 수 있게 선택하자.]
- lowerBound : 파티션 크기에 대한 파티션 열의 최솟값
- upperBound : 파티션 크기에 대한 파티션 열의 최댓값
스파크는 PostgreSQL, MySQL, 애저 코스모스 DB, MS SQL 서버, 아파치 카산드라, 스노우플레이크, 몽고DB 등 다양한 외부 데이터 소스와 견결이 가능하다.
데이터 프레임 및 스파크 SQL의 고차 함수
복잡한 데이터 유형을 조작하는 방법은 데이터를 분해 및 수집, 사용자 정의 함수 사용하는 두 방법이 있다.
이 두 방법은 비용을 많이 잡아먹을 수 있기 때문에, 아파치 스파크에 내장된 함수를 사용할 수 있다.
내장 함수는 배열 유형 함수들과 맵 함수들이 있다.
다양하게 존재하기 때문에 예를 들어 함수들마다 한 개만 적어보겠다.
배열 유형 함수
array_distinct(array <T>) : array<T> 배열 내의 중복을 제거한다.
맵 함수
map_form_arrays(array <K>, array <V>) : map <K, V> 주어진 키/값 배열쌍에서 맵을 생성 하여 반환. 키의 요소는 null을 허용하지 않는다.
고차 함수
내장 함수 외에도 익명 람다 함수를 인수로 사용하는 고차 함수가 존재한다.
몇 개의 고차 함수를 설명하기 위해 임의의 샘플 데이터 세트를 만들자.
from pyspark.sql.types import * schema = StructType([StructField("celsius", ArrayType(IntegerType()))]) t_list = [[35, 36, 32, 30, 40, 42, 38]], [[31, 32, 34, 55, 56]] t_c = spark.createDataFrame(t_list, schema) t_c.createOrReplaceTempView("tC") # 데이터 프레임 출력 t_c.show()
t_c.show()의 결과 transform()
입력 배열의 각 요소에 함수를 적용해 배열을 생성한다.
# transform(array<T>, function<T, U>): array<U> # 온도의 배열에 대해 섭씨를 화씨로 계산 spark.sql(""" SELECT celsius, transform(celsius, t -> ((t * 9) div 5) + 32) AS fahrenheit FROM tC """).show()
transform의 결과 filter()
입력한 배열의 요소 중 부울 함수가 참인 요소만으로 구성된 배열을 생성한다.
# filter(array<T>, function<T, Boolean>): array<T> # 온도의 배열에 대해 섭씨 38도 이상을 필터링 spark.sql(""" SELECT celsius, filter(celsius, t -> t > 38) AS high FROM tC """).show()
filter의 결과 exists()
입력한 배열의 요소 중 불린 함수를 만족시키는 것이 존재하면 참을 반환한다.
# exists(array<T>, function<T, V, Boolean>): Boolean # 온도의 배열에 섭씨 38도의 온도가 있는가? spark.sql(""" SELECT celsius, exists(celsius, t -> t = 38) AS threshold FROM tC """).show()
exists의 결과 reduce()
function <B, T, B>를 사용해 요소를 버퍼 B에 병합하고 최종 버퍼에 마무리 function <B, R>을 적용하여 배열의 요소를 단일값으로 줄인다.
# reduce(array<T>, B, function<B, T, B>, function<B, R>) # 온도의 평균을 계산하고 화씨로 변환 spark.sql(""" SELECT celsius, reduce( celsius, 0, (t, acc) -> t + acc, acc -> (acc div size(celsius) * 9 div 5) + 32 ) AS avgFahrenheit FROM tC """).show()
reduce의 결과
관계형 연산
결합과 조인, 윈도우, 수정에 대해서 설명하겠다.
이런 데이터 프레임 작업을 수행하기 위해서 아래와 같은 작업을 수행할 것이다.
- 두 개의 파일을 가져와 두 개의 데이터 프레임을 만들고, 하나는 공항 정보 데이터 다른 하나는 미국 비행 지연 데이터이다.
- expr(0을 사용해 delay 및 distance 컬럼을 STRING에서 INT로 변환한다.
- 데모 예제에 집중하게 작은 테이블 foo를 만들고, 작은 시간 범위 동안 시애틀(SEA)에서 출발해 샌프란시스코(SFO)에 도착하는 3개의 항공편에 대한 정보만 포함하겠다.
from pyspark.sql.functions import expr # 파일 경로 설정 delays_path = "/databricks-datasets/learning-spark-v2/flights/departuredelays.csv" airports_path = "/databricks-datasets/learning-spark-v2/flights/airport-codes-na.txt" # 공항 데이터 셋 읽어 오기 airports = spark.read.options(header="true", inferSchema="true", sep="\t").csv(airports_path) airports.createOrReplaceTempView("airports_na") # airfpotsna = (spark.read.format("csv").options(header="true", inferSchema="true", sep="\t") # .load(airports_path)) # airportsna.createOrReplaceTempView("airports_na") # 출발 지연 데이터 셋 읽어 오기 delays = spark.read.options(header="true").csv(delays_path) delays = (delays .withColumn("delay", expr("CAST(delay as INT) as delay")) .withColumn("distance", expr("CAST(distance as INT) as distance"))) delays.createOrReplaceTempView("departureDelays") # departureDelays = (spark.read.format("csv").options(header="true").load(delays_path)) # departureDelays = (departureDelays # .withColumn("delay", expr("CAST(delay as INT) as delay")) # .withColumn("distance", expr("CAST(distance as INT) as distance"))) # departureDelays.createOrReplaceTempView("departureDelays") # 임시 foo 테이블 생성 foo = delays.filter(expr(""" origin == 'SEA' AND destination == 'SFO' AND date like '01010%' AND delay > 0""")) foo.createOrReplaceTempView("foo") # foo = (departureDelays.filter(expr(""" # origin == 'SEA' AND # destination == 'SFO' AND # date like '01010%' AND # delay > 0"""))) # # foo.createOrReplaceTempView("foo") ## 공항 정보 데이터 spark.sql("SELECT * FROM airports_na LIMIT 10").show() # 미국 비행 지연 데이터 spark.sql("SELECT * FROM departureDelays LIMIT 10").show() # 3개의 항공편 데이터 spark.sql("SELECT * FROM foo LIMIT 10").show()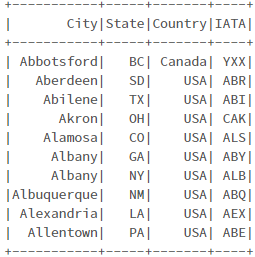
공항 정보 데이터 

왼쪽은 미국 비행 지연 데이터, 오른쪽은 3개의 항공편 데이터 Union
동일한 스키마를 가진 두 개의 서로 다른 데이터 프레임을 함께 결합할 때, Union을 사용한다.
# 두 테이블 결합 bar = delays.union(foo) bar.createOrReplaceTempView("bar") bar.filter(expr(""" origin == 'SEA' AND destination == 'SFO' AND date LIKE '01010%' AND delay > 0""")).show() # bar = departureDelays.union(foo) # bar.createOrReplaceTempView("bar") # bar.filter(expr(""" # origin == 'SEA' AND destination == 'SFO' # AND date LIKE '01010%' # AND delay > 0""")).show() # SQL에서 spark.sql(""" SELECT * FROM bar WHERE origin = 'SEA' AND destination = 'SFO' AND date LIKE '01010%' AND delay > 0 """).show()

왼쪽은 bar.filter.show의 결과, 오른쪽은 SQL의 결과 Join
기본적으로 스파크 SQL 조인은 inner join이며, 옵션은 inner, cross, outer, full 등이 존재하며, 문서에서 확인이 가능하다.
# 출발 지연 데이터(foo)와 공항 정보 조인 foo.join( airports, airports.IATA == foo.origin ).select("City", "State", "date", "delay", "distance", "destination").show() # SQL에서 spark.sql(""" SELECT a.City, a.State, f.date, f.delay, f.distance, f.destination FROM foo f JOIN airports_na a ON a.IATA = f.origin """).show()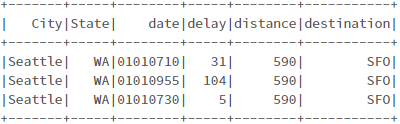

왼쪽은 join의 결과, 오른쪽은 SQL의 결과 윈도우
윈도우 함수는 일반적으로 윈도우 행의 값을 사용하여 다른 행의 형태로 값 집합을 반환한다. 윈도우 함수를 사용하면 모든 입력 행에 대해 단일값을 반환하면서 행 그룹에 대해 작업 할 수 있다.
# SQL 예제 spark.sql("DROP TABLE IF EXISTS departureDelaysWindow") spark.sql(""" CREATE TABLE departureDelaysWindow AS SELECT origin, destination, sum(delay) as TotalDelays FROM departureDelays WHERE origin IN ('SEA', 'SFO', 'JFK') AND destination IN ('SEA', 'SFO', 'JFK', 'DEN', 'ORD', 'LAX', 'ATL') GROUP BY origin, destination """) spark.sql("""SELECT * FROM departureDelaysWindow""").show()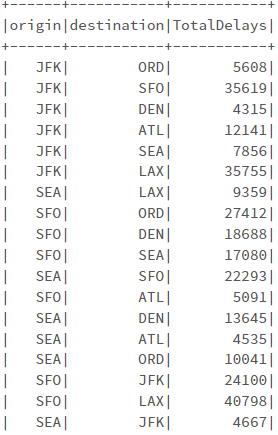
spark.sql("""SELECT * FROM departureDelaysWindow""").show()의 결과 가장 많은 지연이 발생한 3개의 목적지를 찾으려면??
# SQL 예제 1 spark.sql(""" SELECT origin, destination, sum(TotalDelays) as TotalDelays FROM departureDelaysWindow WHERE origin = 'SEA' GROUP BY origin, destination ORDER BY sum(TotalDelays) DESC LIMIT 3 """).show() # SQL 예제 2 spark.sql(""" SELECT origin, destination, TotalDelays, rank FROM ( SELECT origin, destination, TotalDelays, dense_rank() OVER (PARTITION BY origin ORDER BY TotalDelays DESC) as rank FROM departureDelaysWindow ) t WHERE rank <= 3 """).show()두 방법이 있으나, density_rank 같은 윈도우 함수를 사용하는게 더 나은 방식이다.

SQL 예제 2번째의 결과 각 윈도우 그룹은 단일 이그제큐터에서 실행될 수 있어야 하며 실행 중에는 단일 파티션으로 구성된다는 점에 유의하자.
열 추가
foo 데이터 프레임에 새 컬럼을 추가하려면 withColumn() 함수를 사용한다.
from pyspark.sql.functions import expr foo2 = foo.withColumn("status", expr("CASE WHEN delay <= 10 THEN 'On-time' ELSE 'Delayed' END")) foo2.show() # SQL 예 spark.sql("""SELECT *, CASE WHEN delay <= 10 THEN 'On-time' ELSE 'Delayed' END AS status FROM foo""").show()
foo2.show의 결과 열 삭제
열 삭제를 위해 drop() 함수를 사용해야 한다.
foo3 = foo2.drop("delay") foo3.show()
foo3.show의 결과 컬럼명 바꾸기
withColumnRenamed() 함수를 사용하여 컬럼명을 바꿀 수 있다.
foo4 = foo3.withColumnRenamed("status", "flight_status") foo4.show()
foo4.show의 결과 피벗
데이터로 작업 시 로우와 컬럼을 바꿔야 하는 경우가 있다. 이때 피벗을 이용한다.
# 1 spark.sql(""" SELECT destination, CAST(SUBSTRING(date, 0, 2) AS int) AS month, delay FROM departureDelays WHERE origin = 'SEA' """).show(10)
1의 결과 # 2 spark.sql(""" SELECT * FROM ( SELECT destination, CAST(SUBSTRING(date, 0, 2) AS int) AS month, delay FROM departureDelays WHERE origin = 'SEA' ) PIVOT ( CAST(AVG(delay) AS DECIMAL(4, 2)) as AvgDelay, MAX(delay) as MaxDelay FOR month IN (1 JAN, 2 FEB, 3 MAR) ) ORDER BY destination """).show()
2의 결과 # 3 spark.sql(""" SELECT * FROM ( SELECT destination, CAST(SUBSTRING(date, 0, 2) AS int) AS month, delay FROM departureDelays WHERE origin = 'SEA' ) PIVOT ( CAST(AVG(delay) AS DECIMAL(4, 2)) as AvgDelay, MAX(delay) as MaxDelay FOR month IN (1 JAN, 2 FEB) ) ORDER BY destination """).show()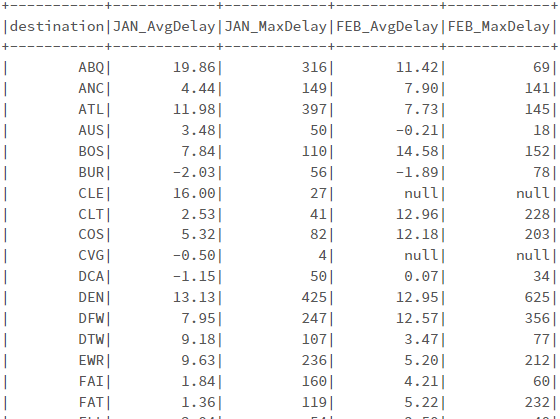
3의 결과 '데이터엔지니어링 > Spark' 카테고리의 다른 글
[6장] 스파크 SQL과 데이터세트 (0) 2023.09.13 [4장] 스파크 SQL과 데이터 프레임: 내장 데이터 소스 소개 [2] (0) 2023.08.03 [4장] 스파크 SQL과 데이터 프레임: 내장 데이터 소스 소개 [1] (0) 2023.08.01 [3장] 아파치 스파크의 정형화 API [2] (0) 2023.07.25 [3장] 아파치 스파크의 정형화 API [1] (0) 2023.07.20