리소스 이해하기
워크로드에 사용 가능한 클러스터 리소스를 최대한 활용하는 동시에 트래픽 폭증, 노드 장애, 잘못된 배포 상황에 대처할 수 있는 충분한 여유 공간을 확보할 수 있는 방법은 무엇이 있을까??
쿠버네티스 스케줄러 관점에서 생각을 해보자. 여기서, 스케줄러는 주어진 파드를 어디에서 실행할지 결정하는 역할을 하는데, "파드를 실행할 수 있는 충분한 리소스를 가진 노드가 있는가?" -> 파드를 실행하는데 얼마나 리소스가 드는지 알아야 답을 할 수 있다.
리소스 단위
파드의 CPU 사용량은 CPU 단위로 표시되며, 쿠버네티스 CPU는 AWS의 vCPU, 구글 클라우드의 코어, AZURE의 vCore와 동일하다. 쿠버네티스 용어로 1CPU는 일반적인 CPU단위로 보면 된다.
대부분의 파드는 CPU 전체가 필요하지 않아 요청과 상한은 millicpus(혹은 millicores)로 표시되며, 메모리는 Byte나 mebibytes(MiB)로 측정된다.
리소스 요청
쿠버네티스의 리소스 요청은 최소 리소스 양을 지정하는데, 어떤 특정 사양의 리소스를 요청하면, 파드는 특정 사양보다 적은 리소스를 가진 노드에 스케줄링이 되지 않는다. 만약, 리소스가 충분한 노드가 없을 경우 여유 용량이 생길때 까지 대기상태로 유지된다.
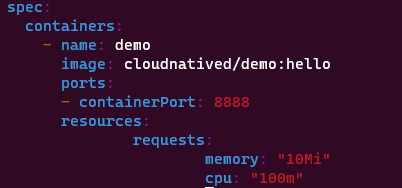
리소스 상한
리소스 상한은 파드가 사용할 수 있는 최대 리소스 양을 지정하는데, 파드가 상한을 초과하여 CPU를 사용하려고 하면, 해당 파드는 제한되며 성능 저하가 발생한다.
상한을 초과하면 파드는 종료되고 다시 스케줄링되며, 동일한 노드에서 파드가 단순히 다시 실행된다.
리소스 상한을 지정해두면 네트워크 서버와 같은 애플리케이션의 수요가 증가했을때, 파드가 클러스터 용량을 과다하게 점유하는 것 막을 수 있다.
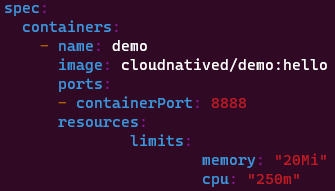
쿠버네티스는 리소스 오버커밋을 허용하는데, 오버커밋은 노드 내 컨테이너의 모든 리소스 상한의 합계가 해당 노드의 전체 리소스 양을 초과할 수 있음을 의미한다. 사실 대부분의 컨테이너가 리소스 상한을 넘지 않을 것이라 가정한다.
쿠버네티스가 파드를 종료해야 한다면 리소스 요청을 가장 많이 초과하는 파드부터 종료한다.
컨테이너를 작게 유지하자
컨테이너 이미지를 작게 유지시 장점
작은 컨테이너는 빌드가 빠르다.
이미지는 저장 공간을 덜 차지한다.
이미지 풀링이 더 빠르다.
보안 취약점이 줄어든다.
컨테이너 생명 주기 관리하기
활성 프로브
쿠버네티스는 컨테이너의 작동유무를 확인하는 헬스 체크를 컨테이너 스펙에 활성 프로브로 지정이 가능하다.
HTTP 컨테이너의 경우 일반적 활성 프로브 스펙은 아래와 같다.
livenessProbe:
initialDelaySeconds: 2 # 첫 2초 딜레이
periodSeconds: 5 # 5초마다 다시 보내기
httpGet:
path: /healthz
port: 8888쿠버네티스가 /healthz의 8888 포트로 요청을 보내고, 2xx or 3xx으로 HTTP가 응답시 활성 상태로 판단하며, 다른 값으로 나오면 컨테이너가 죽은것으로 판단해 다시 실행한다.
프로브 딜레이와 주기
쿠버네티스가 언제 활성 프로브를 검사하도록 할건지는 initialDelaySeconds 필드를 이용하여 첫 번째 활성 프로브를 실행하기 전에 얼마나 기다리는지 쿠버네티스가 알 수 있게 해준다.
그리고, periodSeconds 필드를 통해서 활성 프로브를 검사하는 주기를 지정할 수 있다.
다른 종류의 프로브
HTTP로 서비스하지 않는 네트워크 서버는 tcpSocket을 사용하면 된다.
livenessProbe:
tcpSocket:
port: 8888
##################
readinessProbe:
exec:
command:
- cat
- /tmp/healthytcpSocket은 지정한 포트로 TCP 연결이 성공하면 해당 컨테이너는 살아 있는 것이며, 또한 exec 프로브를 사용하여 컨테이너에 임의의 명령어를 실행할 수도 있다. exec 프로브는 일반적으로 준비성 프로브로 더 유용하게 사용된다.
gRPC 프로브
gRPC에는 대부분의 fRPC 서비스가 지원하는 표준 헬스 체크 프로토콜이 있다. 쿠버네티스 활성 프로브로 헬스 체크를 활용하려면 grpc-health-probe 도구를 사용하면 된다. 이 도구를 컨테이너에 추가하면 exec 프로브를 사용하여 상태를 확인할 수 있다.
준비성 프로브
활성 프로브와 관련이 있긴하나 조금 다르다. 초기화 과정이 길거나 하위 프로세스가 완료될 때까지 오래 기다려야 하는 경우, 애플리케이션은 쿠버네티스에 일시적으로 요청을 처리할 수 없다는 신호를 보내는데, 준비성 프로브가 이 기능을 제공한다.
애플리케이션이 준비를 완료할 때까지 HTTP를 수신하지 않는 경우에 준비성 프로브는 활성 프로브와 동일한 스펙으로 지정해야 한다.
redinessProbe:
initialDelaySeconds: 2 # 첫 2초 딜레이
periodSeconds: 5 # 5초마다 다시 보내기
httpGet:
path: /healthz
port: 8888준비성 프로브 검사에 실패한 컨테이너는 해당 파드가 속한 서비스에서 제거되며, 준비성 프로브가 다시 성공할 때까지 트래픽은 파드로 전달되지 않는다.
minReadySeconds
기본적으로 컨테이너나 파드는 준비성 프로브가 성공하는 순간에 준비가 완료된 것으로 판단한다.
minReadySeconds 필드는 컨테이너나 파드가 minReadySeconds가 될 때까지 준비 상태로 판단되지 않게한다.
PodDisruptionBudgets
때때로 쿠버네티스는 파드가 활성 상태이며 준비 상태이더라도 파드를 중지해야 한다. 예로, 업그레이드 전에 실행 중인 노드를 비우거나 파드를 다른 노드로 옮겨야 할 때가 있다.
특정 애플리케이션에 PodDisruptionBudget 리소스를 사용하면, 주어진 시간에 제거할 수 있는 파드의 양을 제한할 수 있다.
minAvailable 필드는 최소한 실행해야 하는 파드의 개수를 지정한다.
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: demo-pdb
spec:
minAvailable: 3
selector:
matchLabels:
app: demomaxUnavailable 필드는 쿠버네티스가 퇴출할 수 있는 파드의 총 개수나 비율을 제한할 수 있다.
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: demo-pdb
spec:
maxUnavailable: 10%
selector:
matchLabels:
app: demo10% 이상의 데모 파드를 한 번에 퇴출시킬 수 없는데, 이는 오직 쿠버네티스가 시작한 자발적 퇴출의 경우에만 적용된다.
노드를 3개 운영 중이라면 노드 하나에서 장애가 발생 했을 때, 모든 파드의 3분의 1이 손실될 수 있다.
네임스페이스 사용하기
클러스터 전체에서 리소스 사용을 관리하는 또 다른 유용한 방법은 네임스페이스를 사용하는 것인데, 쿠버네티스 네임스페이스는 클러스터를 원하는 목적에 따라 세부 공간으로 나눈다.
네임스페이스라는 용어에서 알 수 있듯이 네임스페이스 안의 이름은 다른 네임스페이스와 격리된다.
즉 prod 네임스페이스 안의 demo라는 서비스와 test 네임스페이스의 demo 서비스가 함께 존재하더라도 충돌이 발생하지 않는다.
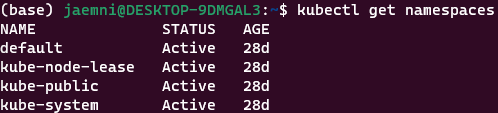
네임스페이스 다루기
kubectl reun과 같은 kubectl 명령어를 실행할 때 네임스페이스를 지정하지 않으면 명령이 기본 네임스페이스에서 실행된다. kube-system 네임스페이스는 쿠버네티스 내부 시스템 컴포넌트가 실행되는 공간으로 애플리케이션과 격리된다.
네임스페이스를 --namesapce 혹은 -n 플래그로 지정하면 명령은 해당 네임스페이스를 사용한다.
kubectl get pods --namespace prod # 예시서비스 주소
네임스페이스는 서로 격리되어 있지만 다른 네임스페이스의 서비스와 여전히 통신할 수 있다.
쿠버네티스 서비스는 외부와 통신 가능한 DNS 주소를 가진다.
서비스 DNS 이름은 항상 다음 양식을 따른다.
SERVICE.NAMESPACE.svc.cluster.local.svc.cluster.local은 선택 사항이며 네임스페이스도 선택 사항이며, prod 네임스페이스에 있는 demo 서비스와 통신하고 싶다면 다음처럼 사용하면 된다.
demo.prod리소스 쿼터
네임스페이스에도 리소스 사용을 제한할 수 있는데, 제한 방법은 네임스페이스에 ResourceQuota를 생성하면 된다.
apiVersion: v1
kind: ResourceQuota
metadata:
name: demo-resourcequota
spec:
hard:
pods: "100"이 매니페스트를 적용하면, 네임스페이스에서 한 번에 실행 가능한 파드의 개수가 100개로 제한된다.

쿠버네티스는 demo 네임스페이스의 쿼터를 초과하는 모든 API 작업을 차단한다.
ResourceQuotas를 사용하면 특정 네임스페이스 내 애플리케이션이 너무 많은 리소스를 사용하여 클러스터의 다른 애플리케이션의 자원을 할당받지 못하는 문제를 해결이 가능하다.
특정 네임스페이스에서 ResourceQuotas가 활성화 상태인지 확인은 아래처럼 하면 된다.
kubectl get resourcequotas -n demo
클러스터 비용 최적화
디플로이먼트 최적화하기
레플리카가 많을수록 애플리케이션은 더 많은 트래픽을 처리할 수 있지만, 클러스터는 한정된 수의 파드만 실행할 수 있기 때문에 파드는 최대한의 가용성을 가져와야 한다.
가능하면, 서비스 저하가 발생하지 않는 선에서 레플리카를 최소화 하는게 중요하다.
파드 최적화하기
워크로드를 정상적으로 처리할 리소스가 필요하며, 리소스 요청보다 10%정도 약간 높게 설정하는게 좋다.
Vertical Pod Autoscaler
쿠버네티스 애드온으로 리소스 요청에 대한 이상적인 값을 정하는 것을 도와주는 아이템(?)이다.
노드 최적화하기
클러스터 용량의 최적화를 위해선 실제 서비스 환경에서 워크로드가 노드에서 어떻게 실행되는지 관찰해야 한다.
일반적으로 노드가 보통의 파드를 적어도 5개를 실행할 수 있을 만큼 크게하며, 버려지는 리소스의 비율을 약 10% 이하로 유지킨다. 노드가 파드를 10개 이상 실행할 경우에는 버려지는 리소스를 5% 미만으로 유지해야한다.
스토리지 최적화하기
많은 클러스터 노드가 실제로 필요한 것보다 많은 양의 디스크 공간을 할당받고 있기 때문에, 이를 적절히 할당하면 된다.
사용하지 않는 리소스 정리하기
쿠버네티스 클러스터 사이즈가 점점 커지면, 잘 보이지 않는 곳에 숨어 있어 사용되지 않거나 관뢰되지 않고 버려진 리소스들이 존재하는데, 이런 리소스들을 정리하자. 그리고 사용하지 않는 인스턴스들을 찾아 제거하자.
실행되지 않는 컨테이너 이미지도 노드의 디스크 공간을 차지하는데, 쿠버네티스는 노드의 디스크 공간이 부족시 사용하지 않는 이미지를 자동으로 정리한다.
소유자 메타데이터를 사용하고, 활용도가 낮은 리소스를 파악하고, 완료된 잡 정리하는 것도 좋다.
완료된 잡 정리하는 도구는 kube-job-cleaner가 있다.
여유 용량 파악하기
클러스터에 항상 여유 공간을 가지는게 중요하다.
예약 인스턴스 사용하기
클라우드에서 비용을 절약할 수 있는 방법이다.
스폿 인스턴스 사용하기
클라우드에서 가용성과 가격 사이에서 타협점을 제공하나, 불시에 일시 중지 되거나 할 수 있다. 하지만, 쿠버네티스는 개별 클러스터 노드의 장애에도 고가용성 서비스를 보장한다는 걸 기억하자.
워크로드 균형있게 유지하기
스케줄러와 디스케줄러 도구를 이용하여 워크로드가 균형을 이루도록 하자.
'데이터엔지니어링 > K8s on Cloud' 카테고리의 다른 글
| [6장] 클러스터 운영하기 (0) | 2023.08.03 |
|---|---|
| [4장] 쿠버네티스 오브젝트 다루기 (0) | 2023.06.20 |
| [3장] 쿠버네티스 구축하기 (0) | 2023.06.06 |
| [2장] 쿠버네티스 첫걸음 (0) | 2023.06.05 |
댓글